
14 Feb Construcción de un modelo de Machine Learning usando TensorFlow (parte 2)
Una vez preparado los datos de entrenamiento, llega la parte entretenida, programar nuestro modelo. Pero para ello empezar necesitamos elegir primero una herramienta que nos permita ejecutar el código Python, aunque Python nos ofrece su propio compilador, en mi caso al no tener un ordenador con una tarjeta gráfica lo suficientemente buena para entrenar el modelo de Machine Learning, he decidido utilizar una herramienta online que nos proporciona Google de forma totalmente gratuita llamada Google Colaboratory para esta labor. Este producto de Google está totalmente integrada en la nube y no consumirá nada de nuestro CPU. Además de ofrecer una GPU o TPU sin coste alguno que nos permitirá acelerar nuestro proceso de entrenamiento para el modelo.
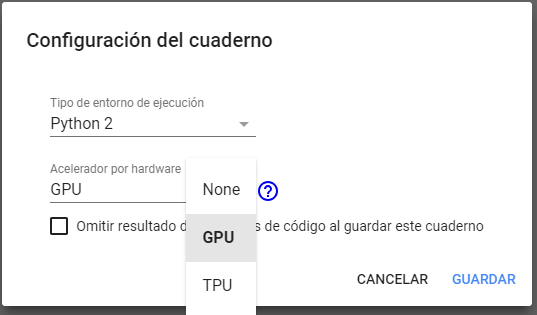
Cabe mencionar que las TPU o también conocidas como Tensor Processing Unit, son unas unidades de procesamiento dedicadas especialmente al entrenamiento de modelos en TensorFlow, sin embargo en mi ejemplo usaremos las GPU ya que son las más comunes y las más sencillas de usar.
Ahora si, es el momento de programar. Para ello accedemos a nuestro cuaderno vacío de Google Colab y accedemos al menú de editar y configuramos el cuaderno, yo para mi ejemplo he usado como entorno Python 2 y GPU como hardware de aceleración.
Una vez definido el entorno, necesitamos instalar la librería de Tensorflow y las dependencias para poder ejecutarla.
Con las dependencias instaladas, el siguiente paso es cargar nuestros datos de entrenamiento en el cuaderno y para ello tenemos dos formas una mediante Google Drive o la de subir el archivo zip directamente desde nuestro ordenador local, yo para automatizar el proceso, he subido mis datos a Drive y lo he descargado utilizando la librería que posee Python para bajarse los archivos de Drive, y una vez descargado se descomprime el archivo con la librería zipFile.

Con los datos ya cargados y la librería de TensorFlow podemos generar los archivos TFRecord para entrenar el modelo, estos archivos son los únicos que entiende TensorFlow y por tanto son imprecindibles para poder entrenar nuestor modelo, ya que contiene toda la información de los datos de entrenamiento que serán utilizados por el modelo para ser entrenado.
Así que para generar estos archivos tenemos que escoger uno de los varios scripts que nos ofrece Tensorflow para crearlos, en mi ejemplo he usado create_pet_tf_record.py. Para generar los archivos solamente hace falta ejecutar al script en el cuaderno como si fuese un comando de la terminal con los párametros necesarios:

Este comando nos generará dos archivos, pet_faces_train.record-00000-of-00001 y pet_faces_val.record-00000-of-00001, el nombre del archivo es estándar debido al script pero podemos renombrarlos a lo que queramos, yo en mi ejemplo los he renombrado a train.record y val.record.
Ahora que tenemos todos los archivos para la entrada, aún necesitamos el modelo a ser entrenado. Lo normal sería crear un modelo desde cero definiendo las capas y entrenarlo con nuestros propios datos. Pero este proceso nos llevaría días o incluso semanas dependiendo de la cantidad de datos que hayamos recolectado. Por ello, para agilizar el proceso, he escogido uno de los modelos ya entrenados que nos proporciona TensorFlow, llamado faster_rcnn_inception_v2, que ya ha sido entrenado con millones de imágenes reales y que solamente necesitaremos re entrenarlo con los nuevos datos y adaptar la salida para la tarea que nosotros queremos.
Por lo que solamente necesitamos descargar el archivo de configuración del modelo y cambiarle los archivos de entrenamiento para entrenar nuestro propio modelo.
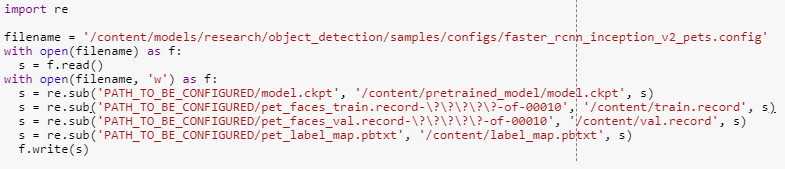
Teniendo el modelo pre-entrenado y los archivos TFRecord, ha llegado el momento de entrenar nuestro modelo. Al igual que hemos hecho para generar los archivos TFRecord, TensorFlow tiene un script que facilita el entrenamiento del modelo nuevo donde solamente tiene que modificar los parámetros de entrada.

El proceso de entrenamiento puede llevar un buen rato dependiendo de la cantidad de datos por lo que podéis a tomar un café mientras tanto. Una vez que haya terminado el entrenamiento TensorFlow nos mostrará la precisión media de nuestro modelo con datos de prueba. Y en caso de que no sea muy alta deberíamos re-entrenar el modelo con más datos.
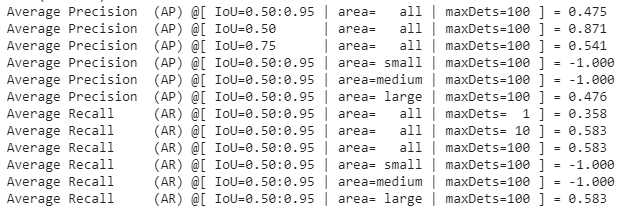
Después de varios intentos intentando subir la precisión, lo máximo que he logrado ha sido un 95% que para los modelos actuales es bastante alta ya. Por lo que podemos ya pasar a la fase de prueba.
Primero tenemos que exportar el modelo para obtener los pesos y el grafo del modelo que nos servirá para la clasificación de imágenes.

Una vez exportado, lo siguiente es cargar los ficheros del nuevo modelo en el cuaderno, además del archivo label_map.pbtxt que creamos al principio del artículo para clasificar los distintos objetivos.

Ya con el modelo cargado, ha llegado el momento que todos esperamos, ¿funcionará bien?, para comprobarlo voy a usar una imagen aleatoria que he encontrado en Google y lo he cargado en el cuaderno con la librería Image.


Para clasificar lo que aparece en esta foto voy a crear un método que mostrará los diferentes objetivos que se encuentran en la imagen.

Y después de tanta espera, el resultado final ha sido ……

Podemos observar que nuestro modelo ha acertado con 99% de seguridad que es un humano y con un 68% y 98% respectivamente que hay dos monos. Pero en la imagen si nos fijamos bien hay 3 monos, por lo que nuestro modelo ha fallado en detectar a este tercero. Esto ha sido a causa de que al ser tan parecidos y estar uno encima del otro el modelo no ha sido capaz de diferenciar ambos por la falta de datos de entrenamiento con ejemplos parecidos o donde se produzcan casos que no tenemos en nuestros datos iniciales.
Con esto podemos concluir que, aunque nuestro modelo no haya logrado clasificar totalmente la imagen, tiene una precisión bastante alta para los casos generales donde se diferencian bien al individuo, pero que aún así, se puede mejorar más añadiendo nuevos datos y situaciones diferentes para que nuestro modelo reconozca más casos, ayudando así a elevar aún más la precisión.